Researchers at the University of Toronto’s Department of Psychology suggest that current augmented-reality heads-up display (AR-HUD) technology poses a safety threat. In a recent study published in PLOS ONE, Professor Ian Spence and his students Yuechuan Sun and Sijing Wu identified a gap in scientific research with regards to the allocation of visual attention.
Specifically, in the distribution of attentional resources during tasks involving stimuli that are non-contiguous, but spatially commingled. Use of AR-HUD requires commingled division of visual attention.
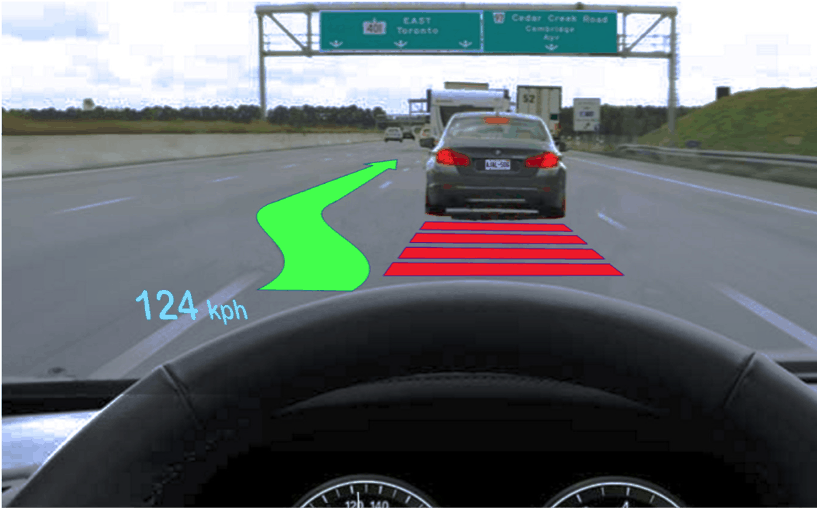
AR displays consist of a graphic overlay that integrates information with the driver’s forward view virtually, with the aim of directing and enhancing the driver’s attention to particular visual features within their environment.
“I think that the most problematic information in an AR-HUD is a sudden-onset safety-related graphic,” said Spence. “This will capture attention and necessarily reduce the attention remaining for dealing with objects and events in the forward field of view. Whether this is dangerous or not will depend on how heavily attention is loaded. If there is little excess capacity to deal with the warning, reciprocal interference seems inevitable.”
To measure reciprocal interference between a primary and secondary task, researchers measured accuracy and reaction times across two experiments. The primary task consisted of a series of computer-based enumeration trials with a varying load (one to nine dots). Participants were given an incentive to respond as quickly and accurately as possible.
In the first experiment, the secondary task consisted of reporting the presence or absence of a secondary stimulus that appeared after dot displays at a relatively low probability. In the second experiment, participants had to report the shape of the secondary stimulus (square, triangle, or diamond).
The appearance of the secondary stimulus renders the task analogous: the occasional appearance of visual warnings in an AR display, and the shape identification condition in the second experiment, gave an indication of whether or not the secondary stimulus was clearly seen.
Results show that the effects of the secondary task on accuracy and reaction time support concerns for public safety. Comparing results between first and second experiments shows that shape identification comes at a cost to speed and accuracy. Results from the second experiment alone show that the appearance of the secondary stimulus reduced accuracy on the primary task by 13 per cent and nearly tripled the average response time.
Experimental results do not suggest that the primary task of “safe driving” will be uncompromised or even supported by the appearance of sudden-onset visual warnings in an AR display. “These will divert attention during a critical phase and may very well be worse than no warning at all,” says Spence.
Spence and his team find their data can be described by a biased competition model — in said model, attention is allocated based on competition between tasks and sensory inputs compete for processing resources and representation in the brain.
Notably, competition will be more intense for spatially commingled stimuli due to closer proximity of their representation in the brain.
Further, AR-HUD is not necessarily effective in preventing accidents when a driver is not already attending to potential hazards on the road. “After all, the driver should be looking forward (and outside) with a view to recognizing such situations anyway,” says Spence. “If the driver is not attending to the road, the AR-HUD is unlikely to make things better. Autonomous assisted braking or steering is probably a better place for the manufacturer to invest the R&D dollars.”
Spence does not believe that the discrepancy between the intended purpose of AR-HUD and human performance on tasks involving commingled division of visual attention stems from any single, explicit assumption being made by manufacturers. However, he will admit that he believes there is merit to the information. “I think that the dominant notion is that presenting information in the forward field of view is better than having the driver look down to see it. That may well be true; it may indeed be the best-worst solution. But the unanswered question is: “is it better not to present the information at all?”